今天弄个图文并茂的给大家说下,其实dede采集还是很好用的,我发的这个是5.1版的采集教程:
首先看下图:
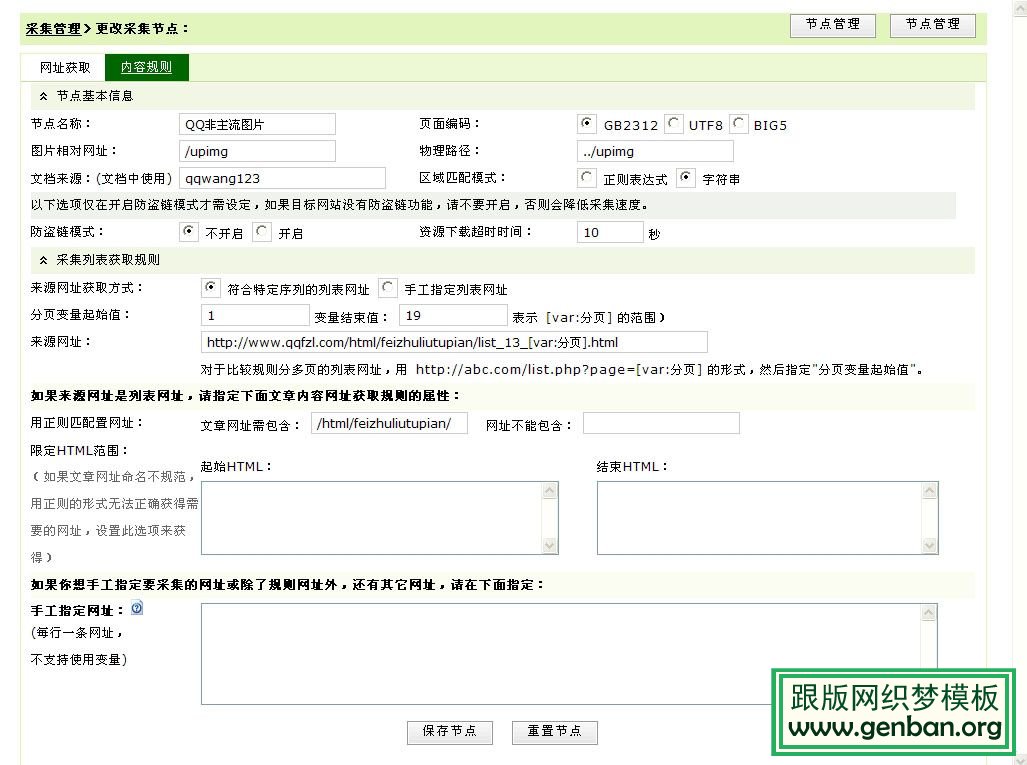
节点名称随便写自己记住就行了,编码按照采集网页自己定制,然后其他没特殊要求默认就好了,然后是分页列表页面。
采集列表获取规则:
来源网址获取方式:自己选择这里我选的第一个
分页变量起始值:分页的变量这个应该明白吧大家。
来源网址:根据页面的分页列表url形式就好了,截图里有大家可以看看!
文章网址需包含:这个就是说列表页每个链接文章的url里面都包含的那字符串
网址不能包含:一般不用写
其他留空就好了,好了下面介绍采集内容页面的填写。
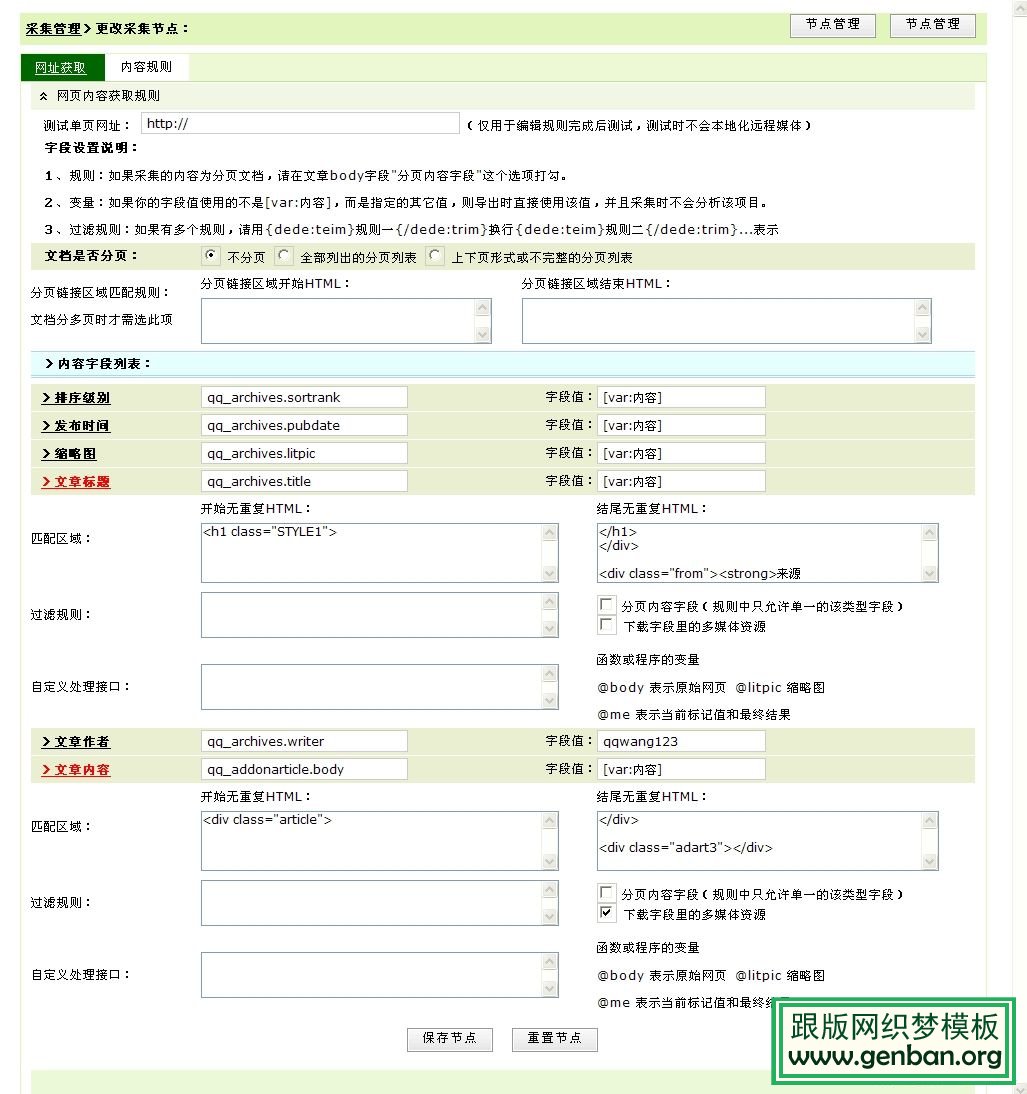
文章标题:
里面的标题代码是
”<div id="content" class="common">
<h1>漂亮的色彩溶解渐变插画图片</h1>
<p id="meta">上传时间:2009-01-07 作者:网络 来源:网络</p><iframe marginwidth="0" marginheight="0" "
大家截取标题的话就是截取
开始无重复HTML:
<div id="content" class="common">
<h1>
结尾无重复HTML:
</h1>
<p id="meta">
就是开始和结尾别重复了就行了,然后符合每个页面的代码规则就好了。(截图是比较早的采集页面,原网站如果有改动请自己改动,图作为参考而已)
然后下面的都按照采集标题的规则去设置就好了,好了大家可以试试祝大家成功有问题可以交流!
本站部分内容来源互联网,如果有图片或者内容侵犯您的权益请联系我们删除!